

How I Tried to Get Rich Using Web Scraping
A deep dive with tech, tips, and lessons learned

I am a developer currently living in Greenville, SC, USA. When I'm not coding, or writing about coding, I enjoy playing tennis and chess competitively.
Disclosure: I get a small commission from sign-ups via links on this page, at no additional cost to you.
I've been a tennis player and fan of the pro tour my whole life. Since sports betting in the US was legalized, I've seen some friends of mine make ridiculous bets on tennis matches. Even with my knowledge of the game and pro players, I can't stomach betting on matches as it seems too unpredictable. What if there was some way I could predict who was going to win matches well enough to win money in the long run?
Sure, this isn't a new idea. People have built elaborate sports betting models to predict outcomes well enough to make them rich, but it's difficult and risky. Casino oddsmakers have machine learning algorithms and an ocean of data at their disposal when setting betting lines, making it tough for amateur gamblers to win money over time. I'm always up for a challenge, so I formulated a plan to make smarter bets on tennis matches and dreamed of making easy money.
In this post, I'll share my plan and how it evolved, what technologies worked for me, and what I learned about them. I'll be discussing Python, Beautiful Soup, APIs, PostgreSQL, SQL, PLpgSQL, and launchd. This is not intended to be a step-by-step tutorial, but rather a way to show my decision-making through the entire stack.
Here is the GitHub Repository for this project if you'd like to follow along. Relevant code samples are included in this post.
My Master Plan
Step 1: Make a good bet
My core idea was simple, but why start complicated? To decide who to bet on for a given match, I needed two pieces of data:
The betting odds for an upcoming match
A prediction of who will win
American Betting Odds
American betting odds are based on a bet of $100, though you can bet any amount. Each player has odds associated with them to show how much you can win with your bet. There are odds for the money line, point spread, and many other bets. We are using the money line, which is only based on the win-loss outcome of the match.
The favorite's odds are usually negative. Odds of -170 mean if you bet $170, you make $100 if that player wins (plus your original bet of $170).
The underdog's odds are usually positive. Odds of 200 mean that if you bet $100, you make $200 if that player wins (plus your original bet of $100).
Of course, if your player loses, you lose your bet!
Heavily lopsided matchups may have odds of -900/+700, while more even matchups may have odds of -150/+110. Casinos set these odds in such a way that they will probably make money no matter what, given a large enough number of people placing bets.
This information is already out there on the internet, I would just need to figure out the best way to bring it into my program to do the calculations.

Predicting The Winner
This part was a mystery for a while. At first, it seemed like I would need to build a separate program involving AI to determine this, which would have been a very deep rabbit hole. I stumbled upon a website called Ultimate Tennis Stats, which has a treasure trove of pro tennis data and built-in analytics.
They have a feature that allows you to set up a hypothetical tennis match between any two players, and it will output a probability of who will win as a percentage. For example, as of the time of writing, it predicts that Novak Djokovic has a 74.2% chance of winning against Rafael Nadal. Novak just won the Australian Open and Rafa has had some injuries lately, so this seems reasonable. This number is just what I needed to continue!
Credit to the Ultimate Tennis Stats team for building an amazing tool.
Putting It All Together
Remember, I'm not just betting on who the prediction says will win the match. I want to make bets that will win money over time factoring in the odds for both players. To do this, I imagined that the players would play 1000 matches, with the match results being split based on the predicted win probability. Then I'd calculate my payout if I bet $1 on player 1 for all matches vs player 2 for all matches. Whichever bet had the higher payout would be my choice. If both bets lose money, I would skip betting on this match entirely.
Here is a table to show the calculation. The light green fields are the inputs for each bet, and the player with the higher positive value in row 7 is my choice.

Step 2: Simulate bets
Before wagering a single cent, I wanted to ensure that this method would actually make money. I needed to simulate bets on real tennis matches as a risk-free proof of concept for my idea, rather than bet real money and find out the hard way.
In addition to the odds and win prediction before the match, I would also need to pull in the results of the match afterward so I could simulate a bet result in terms of dollars. If I bet $1 per match, a win on a player whose odds are +320 would earn me $3.20, while a loss would lose my $1 bet. As more matches are played, I would track my simulated earnings over time and store the results in a database for analysis.
Step 3: Automate bets with real money
If my hypothesis in step 2 is correct and the simulation shows a positive return, the next step would be to automate bets with real money, and get rich!
Time for Action
Designing the Simulation
Now that I had a plan for individual bets, I needed to build out my program to simulate them over multiple matches. The structure of the program would be simple - a single script file that would gather the data from the web, crunch the numbers, and output the results to a database. There would be no need for a graphical user interface. For these reasons, Python was an obvious choice of language to use. It is a multi-purpose, open-source scripting language with many packages that can be used to extend its functionality. Not to mention, the syntax is easy to read and it's a joy to work with.
There are two main objectives for the script
Create bet decisions for upcoming matches
Determine the simulated payout for completed matches
In my script, the updates come first as it made more sense to me to update completed matches before predicting future matches, but these sections could be run in either order.

Gathering the Inputs
I needed to reach out to the web to pull the odds and a win prediction into my program. This is a classic use case for an API (Application Programming Interface), a typical way for applications to communicate over the internet. However, many customer-facing casino odds APIs aren't free, and I still wasn't sure if this project would make any money. I also needed a way to get the win probability from Ultimate Tennis Stats.
This information is available publicly on the web, and after some research, I found that web scraping was what I needed. It's a programmatic way to pull in data from a human-readable web page. Web pages are made up of HTML, CSS, and JavaScript, where HTML represents the raw content of the page. Its main purpose is to provide a user with information after it is styled by CSS and made functional by JavaScript, but it can also be read by search engines for SEO.
Web scraping in itself is completely legal as long as the data is publicly available. However, there are some ethical issues you should consider to make sure your program isn't breaking other laws regarding personal or copyrighted data. For example, I wouldn't recommend scraping personal information to sell without permission. Check out this article for more information on ethical web scraping.
To recap, the three pieces of data that I needed for each match were
Betting odds for the match
A prediction of who will win
The results of the match
I had chosen my website for the prediction, so I went ahead to see if I could scrape it into my program. The most popular Python package for web scraping is called Beautiful Soup, so I installed it into my project directory. The magic is its ability to turn a long string of HTML as text into a BeautifulSoup object, which can be easily parsed with its built-in functions to extract the desired data.
Here is the web page with the probability I was trying to scrape.
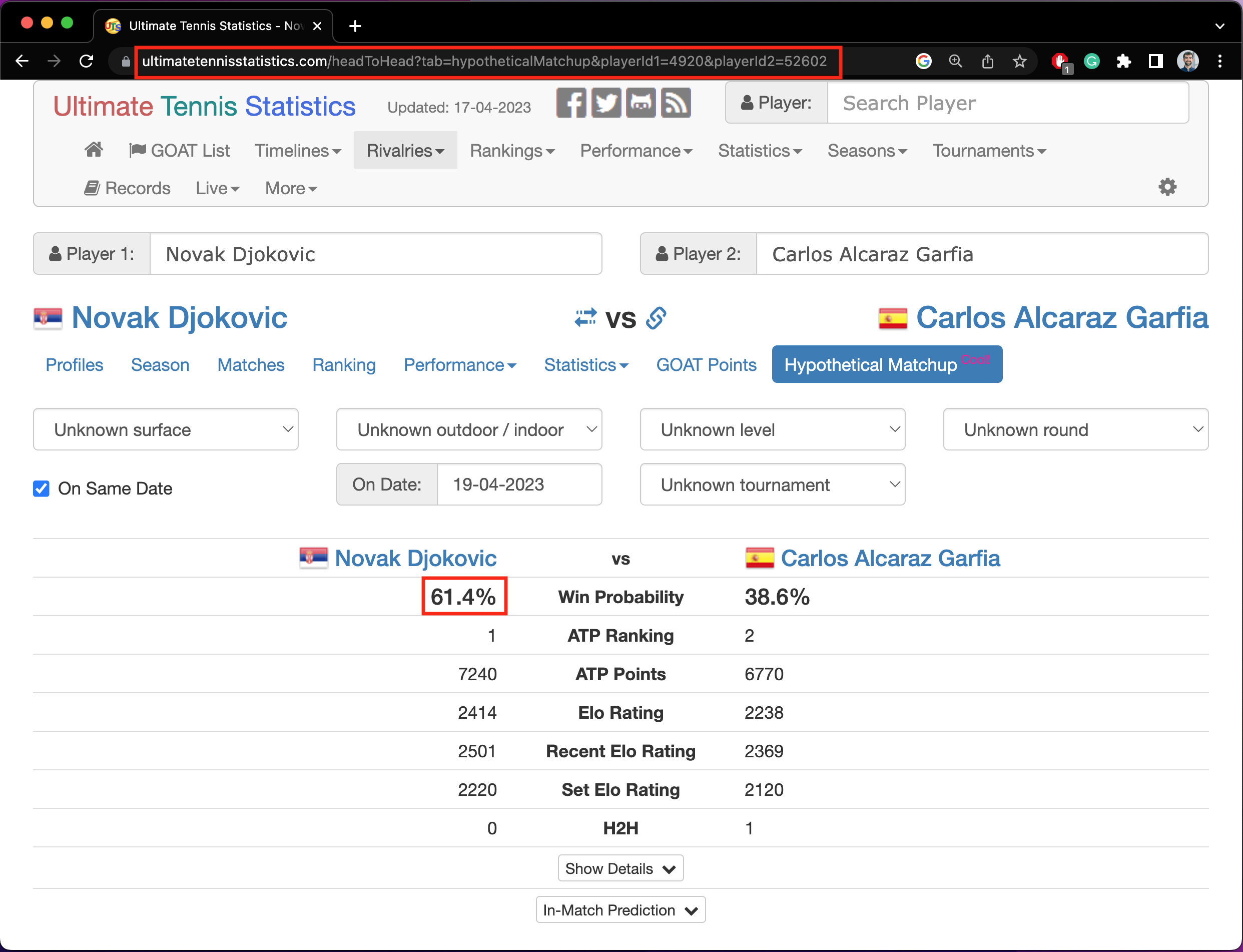
This is a hypothetical match between the 2 top-ranked male players at the time of writing, but this could show any two players by manipulating the player IDs in the URL. I only need player 1's win probability as the other is dependent on it. Let's try to scrape this information with a demo program, demo.py, first without Beautiful Soup to get the raw HTML as text.
import requests
session = requests.Session()
p1_id = 4920 # Novak Djokovic
p2_id = 52602 # Carlos Alcaraz
url = f'https://www.ultimatetennisstatistics.com/headToHead?tab=hypotheticalMatchup&playerId1={p1_id}&playerId2={p2_id}'
response = session.get(url, headers={'User-Agent': 'Mozilla/5.0'})
print(response.text)
Here, we are using the built-in Python requests package to make a call to the URL of the web page. The session allows us to make the request and store additional parameters like the request header. Some websites block web scraping by checking the user agent, which has a default value similar to python-requests/2.25.0 depending on your version of Python. We need to change the User-Agent header to simulate a request from a browser so we are less likely to be blocked. I'm using Mozilla/5.0 but there are others that will work.
The IDs are Ultimate Tennis Stats' internal IDs for each player. I pulled them out of the URL as those will be determined dynamically later on depending on the upcoming matches. We can run this program by opening the terminal, cd-ing into our project directory, and running python3 demo.py. We get a long string of HTML as text, just as we were hoping. Great!
Now let's try parsing it with Beautiful Soup to find the probability. I used Beautiful Soup's find function to navigate the object and find where the text "Win Probability" is on the page, as I know the value isn't far away.
import requests
from bs4 import BeautifulSoup
session = requests.Session()
p1_id = 4920 # Novak Djokovic
p2_id = 52602 # Carlos Alcaraz
url = f'https://www.ultimatetennisstatistics.com/headToHead?tab=hypotheticalMatchup&playerId1={p1_id}&playerId2={p2_id}'
response = session.get(url, headers={'User-Agent': 'Mozilla/5.0'})
doc = BeautifulSoup(response.text, 'html.parser')
win_prob_row = doc.find(string='Win Probability')
print(win_prob_row)
But when I run it, I get a surprise 😱

None!? I can see the element on the page, so what's going on? After searching the HTML provided by that URL, the text "Win Probability" was, in fact, not there at all. So how was it showing up on the page?
The issue is that not all of the data is loaded immediately. The rest is being loaded from separate API calls after the initial page request. I found that it is common for web scrapers to request data from these API endpoints directly, rather than requesting just from the page URL. The response can come back as HTML, JSON, XML, or other formats.
You may be wondering - didn't I say earlier that using an API wasn't an option? I was referring to customer-facing APIs, where access is officially supported for building applications. The APIs that web pages use internally are not supported for external use (like web scraping) and can change frequently. Web scraping programs often require maintenance because the data can change without warning.
By checking the Chrome dev tools Network tab, we can find the API call the page makes to get the probability.
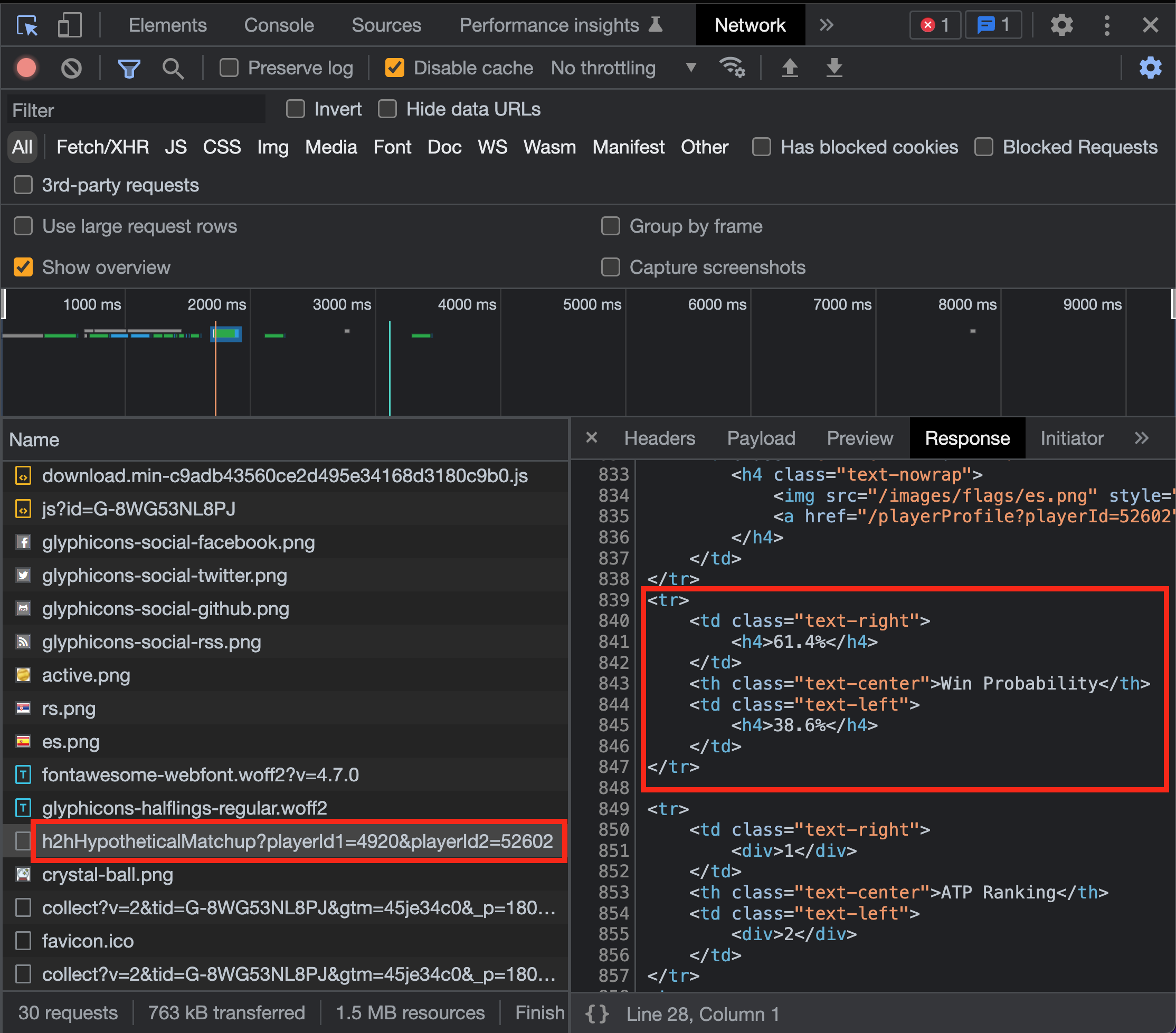
Bingo! The probability is in our sights now. The response format is HTML, so we can continue to use Beautiful Soup to parse it. Let's replace the URL currently in our code with the URL for the API (full URL shown in the Network > Headers tab).
import requests
from bs4 import BeautifulSoup
session = requests.Session()
p1_id = 4920 # Novak Djokovic
p2_id = 52602 # Carlos Alcaraz
url = f'https://www.ultimatetennisstatistics.com/h2hHypotheticalMatchup?playerId1={p1_id}&playerId2={p2_id}'
response = session.get(url, headers={'User-Agent': 'Mozilla/5.0'})
doc = BeautifulSoup(response.text, 'html.parser')
win_prob_row = doc.find(string='Win Probability')
print(win_prob_row)

Now we have the correct BeautifulSoup object, so we just need to do a little more manipulation to get the probability.
import requests
from bs4 import BeautifulSoup
session = requests.Session()
p1_id = 4920 # Novak Djokovic
p2_id = 52602 # Carlos Alcaraz
url = f'https://www.ultimatetennisstatistics.com/h2hHypotheticalMatchup?playerId1={p1_id}&playerId2={p2_id}'
response = session.get(url, headers={'User-Agent': 'Mozilla/5.0'})
doc = BeautifulSoup(response.text, 'html.parser')
win_prob_row = doc.find(string='Win Probability')
p1_win_prob = float(win_prob_row.parent.parent.find('h4').contents[0].replace('%', ''))
print(p1_win_prob)

Success! 🎉 Calling the API endpoints directly is now my preferred web scraping method. I experimented with several other sites to find the remaining numbers I needed, then I used this method to bring them into the project. Some endpoints returned JSON data, which can be parsed with the built-in "json" Python package rather than with Beautiful Soup.
After finishing this project, I found a tool called ScraperAPI that would have made life easier here. It allows scraping programs to bypass IP restrictions, retry automatically, execute JavaScript, and do many other things so that you don't need to scour the web to find a scrapable site like I did. They have a nice free plan to get started.
Configuring the Database
There are several reasons I needed to store data. First, the bet decision needs to be made before the match is played. I had to store it so that the program can check it against the result once the match is played to calculate the simulated payout. Second, the results need to be stored so that the total simulated payout can be calculated.
I chose PostgreSQL (Postgres) as the database since it is a free, open-source, relational database and is popular at the enterprise level. I could have used something simpler like Google Sheets or even Excel, but this was a perfect opportunity for me to get my hands dirty with SQL.
Originally, I wanted to host the database and the program online so that this could run around the clock, but I decided to keep everything running locally on my computer for simplicity. Running the program a few times a day would be sufficient to get the match odds, win predictions, and results, and I could do that manually to start. I installed Postgres locally as well as pgAdmin, a program where I could easily write SQL statements and manage the data. I set up a table named matches with the following columns, which evolved over time as I realized what I needed.
| Column Name | Description | Postgres Data Type |
| Unique ID | Uniquely enforced identifier for each table row (Primary Key in table) | Integer |
| Player 1 Name | Player 1's full name | Character varying (255) |
| Player 2 Name | Player 2's full name | Character varying (255) |
| Player 1 Probability | The predicted percentage that Player 1 will win | Double precision |
| Player 1 Odds | Player 1's betting odds | Integer |
| Player 2 Odds | Player 2's betting odds | Integer |
| Player 1 Total | The simulated payout after 1000 matches | Double precision |
| Player 2 Total | The simulated payout after 1000 matches | Double precision |
| Decision | 0 (no bet), 1 (bet on player 1), or 2 (bet on player 2) | Integer |
| Bet Result | Calculated payout based on a $1 bet, after match completion | Double precision |
| Start Epoch | Epoch time of the match start | Big integer |
| DateTimeUTC | UTC time of the match start | Timestamp without time zone |
| Match ID | The ID of the match from the odds site | Integer |
The next piece of the puzzle was connecting my Python script to the Postgres database. I needed to create SQL statements and send them to the database for execution. I found psycopg2, which is the most popular Postgres database adapter for Python, and installed it into my project. With this tool, I could now open a connection to my database, send it a string of SQL to execute, and close the connection when completed.
Crunching the Numbers
The Bet Prediction
Previously, the prediction we've referred to is the external prediction of who will win the match, which we scraped from Ultimate Tennis Stats. Now, the prediction we're referring to is the program's prediction of who to bet on - the Decision column in the database. In hindsight, my variable naming could have been more clear. 😅
Once the program scrapes what the upcoming matches are along with each player's betting odds, it can determine who to bet on. Here is the calculation of its prediction in Python. I've taken the betting odds scraped earlier and distilled them into p1 and p2 objects for each match, which have the properties name and odds for each player. p1_win_prob is the probability that we scraped earlier (61.4 in our example).
def get_factor(odds):
if odds >= 0:
return abs(odds)/100
else:
return 100/abs(odds)
def make_prediction(p1_win_prob, p1, p2):
sim_p1_wins = p1_win_prob * 10
sim_p2_wins = 1000 - sim_p1_wins
p1_win = sim_p1_wins * get_factor(p1['odds'])
p1_lose = sim_p2_wins * -1
p2_win = sim_p2_wins * get_factor(p2['odds'])
p2_lose = sim_p1_wins * -1
p1_total = p1_win + p1_lose
p2_total = p2_win + p2_lose
global prediction
if p1_total < 0 and p2_total < 0:
prediction = 0
else:
if p1_total > p2_total:
prediction = 1
else:
prediction = 2
return [p1_total, p2_total, prediction]
The function get_factor determines how much money you win per dollar bet if that player wins. Then in make_prediction, it follows the same logic as shown earlier in the table.
Find the predicted number of wins for each player out of 1000 matches. In our example, it would be 614 for player 1 and 386 for player 2.
Find the total (net) payout after all wins and losses for a bet on each player
Bet on the player with the higher positive total. If neither is positive, don't bet.
It now has all the data it needs to upload its match prediction to the matches table as "Decision". First, it formats the relevant match data into a string, representing a single row insertion to the table.
def create_row_string(event):
[p1, p2, start_epoch, match_id] = unpack_event(event)
p1_win_prob = get_win_prob(p1, p2)
[p1_total, p2_total, prediction] = make_prediction(p1_win_prob, p1, p2)
row_string = f"""(DEFAULT, '{p1['name']}', '{p2['name']}', {p1_win_prob}, {p1['odds']}, {p2['odds']}, {p1_total}, {p2_total}, {prediction}, {start_epoch}, {match_id}, '{convert_time(start_epoch)}')"""
return row_string
These strings are used to build an INSERT SQL statement to upload all of them into matches. The betresult column is excluded since the matches haven't happened and do not have results yet.
def insert_new_matches(match_data):
start_string = f"""INSERT INTO {db_table} (Id, Player1Name, Player2Name, Player1Prob, Player1Odds, Player2Odds, Player1Total, Player2Total, Decision, StartEpoch, MatchId, DateTimeUTC) VALUES """
value_string = ', '.join(list(map(create_row_string, match_data)))
where_string = ' ON CONFLICT (MatchId) DO NOTHING'
insert_string = start_string + value_string + where_string + ';'
util.sql_command(cur, conn, insert_string)
The Simulated Payout
After the matches have been completed, we can come back and calculate the payout (betresult) based on a bet of $1 on each match. All we need for that is
The betting odds
Our bet decision from the previous step
The result of the match
The odds and decisions are already in our database, and we can scrape the match results from the web, so what's the best way to do this calculation for each match? There were two approaches I could take.
Pull the decision and odds out of the database, do the calculation in Python, and send the
betresultback to the database.Send the match result to the database first, do the calculation at the database level, and update the match rows with the
betresult.
With option 1, I already had most of the logic for determining a betresult in Python, but I would have to make two SQL commands for each match: SELECT and UPDATE. With option 2, I would have to rewrite some of the logic as a function in SQL, but I would only need one SQL command per match: UPDATE. While option 1 may have been easier, option 2 seemed more efficient since the number of database calls was reduced.
First, I defined the SQL function get_bet_result. It takes the winner and loser of the match as parameters, pulls in the decision and odds from the table, and calculates the payout. PLpgSQL is a language built into Postgres that allows you to define functions and other logic to execute at the database level. I wrote out the function as a string in the Python script, and when the script runs it sends a CREATE command to the database to define it. The function is long so check out my repo if interested. Then, for each match, the program sends an UPDATE command that sets the betresult column to the returned value from get_bet_result(winner, loser) for the row in the table that correlates to the same match as the results.
def update_match(match_result):
winner = util.sanitize(match_result[0])
loser = util.sanitize(match_result[1])
update_string = f"""
UPDATE
{db_table}
SET
betresult = get_bet_result('{winner}', '{loser}')
WHERE
(player1name LIKE '%' || '{winner}' || '%' OR player2name LIKE '%' || '{winner}' || '%')
AND (player1name LIKE '%' || '{loser}' || '%' OR player2name LIKE '%' || '{loser}' || '%')
AND CAST(EXTRACT(epoch FROM NOW()) AS BIGINT)*1000 - startepoch < 345600000;
"""
util.sql_command(cur, conn, update_string)
Now that we can simulate payouts, we can get a sense of if this is a viable strategy! Let's open pgAdmin and check out our table.

Here is a close-up view of the first row.


In this match, Baez is the favorite against Darderi based on the odds and the win probability. Our program simulated a gain of $68.17 after 1000 $1 bets on him and a loss of $274.30 after the same bets on Darderi. Therefore, the decision is 1 (Baez, player 1). The betresult column is positive, meaning Baez won the match and we won our bet! We gained $0.41 on a hypothetical $1 bet.
Any match with a decision of 0 means we didn't bet on it, so the betresult is automatically 0. If match results aren't found, then betresult stays null. The odds data and match result data are coming from two different sources, so sometimes we don't get results. Oh well.
Running the Program
I can run the program manually now, but the ATP Tour doesn't wait for me. Matches are played all the time around the world, so I needed to automate running this script to gather the odds and results around the clock. I mentioned before that ideally this would run on a cloud server that is always alive, but for simplicity and cost, it's running locally on my computer.
I found a program called launchd, which allows Mac users to run programs automatically as long as the computer is awake. This is installed on Mac computers by default to run processes in the background. To add my own process, I needed to add a special .plist file to the /Library/LaunchAgents directory on my computer. Here's what it looks like.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>launchd_tennis_predictions</string>
<key>RunAtLoad</key>
<true/>
<key>ProgramArguments</key>
<array>
<string>/usr/bin/python3</string>
<string>/absolute/path/to/index.py</string>
</array>
<key>WorkingDirectory</key>
<string>/absolute/path/to/working/directory</string>
<key>StartInterval</key>
<integer>3600</integer>
<key>StandardOutPath</key>
<string>/absolute/path/to/out.log</string>
<key>StandardErrorPath</key>
<string>/absolute/path/to/error.log</string>
</dict>
</plist>
The format is an HTML-like list of key-value pairs with the settings. All file and directory paths need to be absolute paths.
Label - a name for the program
RunAtLoad - whether or not to run when the computer boots up
Program Arguments - an array of string arguments. Think of it as the arguments you would type in the command line. Instead of
python3 index.py, it would be /usr/bin/python3 /absolute/path/to/index.py.Working directory - absolute path to the directory holding your program file
Start Interval - the number of seconds between each execution
Standard Out Path - absolute path to the file logging any output messages, such as print statements.
Standard Error Path - absolute path to the file logging errors.
Now my file runs every hour as long as my computer is awake. I set up the scraping to pull odds for all available upcoming matches and match results for the last few days so that I have the best chance of gathering those while I use my computer normally for other things.
Testing
During development, I didn't want to run untested SQL commands on my table of real data, so I needed a test table. I created a matches_test database table and an index_test.py script file to act as my test environment. The script file checks its own file name and uses the corresponding database table. All development can be done in index_test.py and matches_test, then when I'm satisfied with the results I just copy index_test.py to index.py. It's not the most robust test environment but it works well enough for my needs.
The Results
The measure of success for my hypothesis is simply the sum of the betresult column, across all matches. Here is the SQL statement I used to get the sum, along with the total dollars bet and rate of return on our simulated investment.
SELECT
SUM(betresult) AS payout,
COUNT(betresult) AS dollars_bet,
SUM(betresult)*100/COUNT(betresult) AS rate_of_return
FROM
matches
WHERE
betresult != 0 AND betresult IS NOT NULL;
I wrapped this in another Python script called get_result.py so that I could quickly check from the terminal rather than booting up pgAdmin. Drumroll, please!

After about 6 months, the program made predictions on 909 matches. Some match results were missed if my computer was off for a while, and some matches it chose not to bet on. After simulating $366 in bets, we have a loss of $48.60 for a rate of return of -13.28%. Darn!
The script showed that this method in particular would not make money, but I was successful in testing my idea for free! While this program did not make me rich, I gained a wealth of knowledge and had a blast while doing it.
The End
I hope you enjoyed this post! Please leave a like and a comment as I would love to hear your feedback. Was there a flaw in my logic? Could I have improved this somehow? Let me know!





